[Productivity] How to move tables to Excel when PDF won't copy (feat. PDF OCR recognition)

안녕하세요, 김홍시입니다.
최근에 다양한 데이터를 다루게 되면서 PDF 자료를 복사할 일이 생겼는데요,
몇몇 PDF의 경우 복사가 제한되는 상황이 있습니다.
오늘은 그런 복사 제한된 PDF의 표 부분을 어떻게 하면 엑셀로 옮길 수 있는지 알아보겠습니다.
문제상황
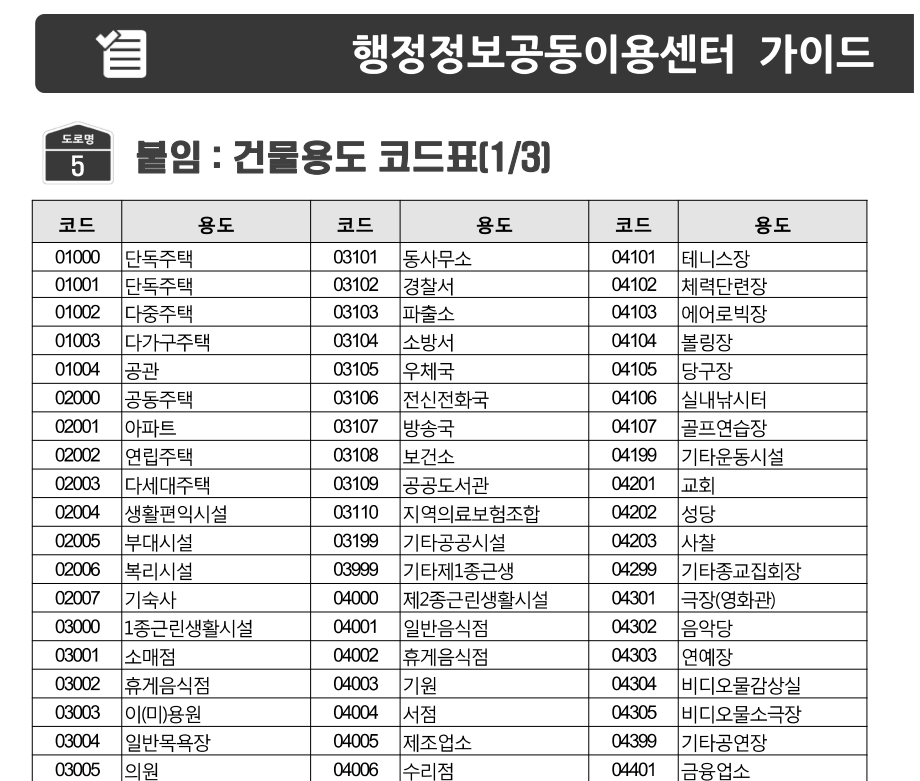
이 파일의 내용을 복사하고 싶은데
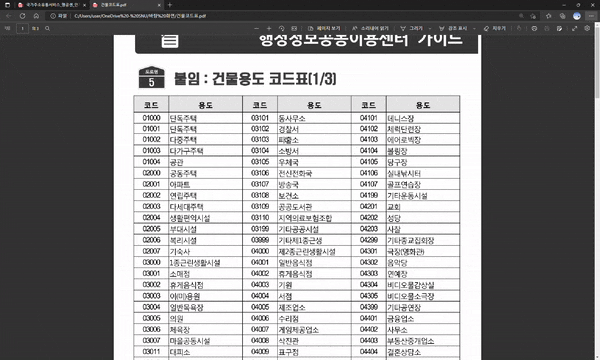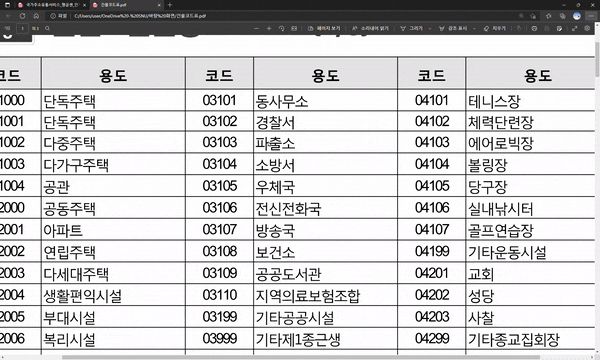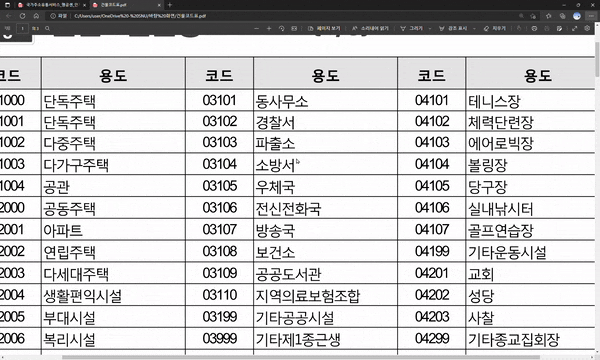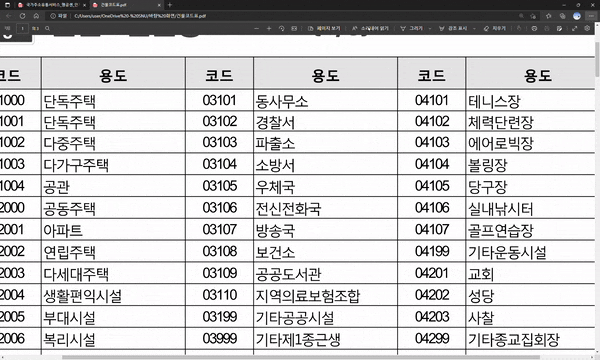
보시는 바와 같이 이렇게 블록처리가 되지 않아 복사를 할 수가 없는 상황입니다.
문제 해결
PDF의 복사 해제를 하기 위한 다양한 방법들이 있는데요, (온라인 PDF 제한 풀기 사이트 이용 등)
오늘은 알PDF의 OCR 인식 기능을 사용해보겠습니다.
먼저 알PDF 프로그램을 실행한 후 홈화면에서 '문자인식(OCR)'을 누릅니다.

OCR?
광학 문자 인식(Optical character recognition; OCR)은 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것이다.
OCR은 한 마디로 말해서 이미지 속 글자를 텍스트의 형태로 변환시키는 것이에요.
그런 후 이용하고 싶은 PDF를 열어줍니다.
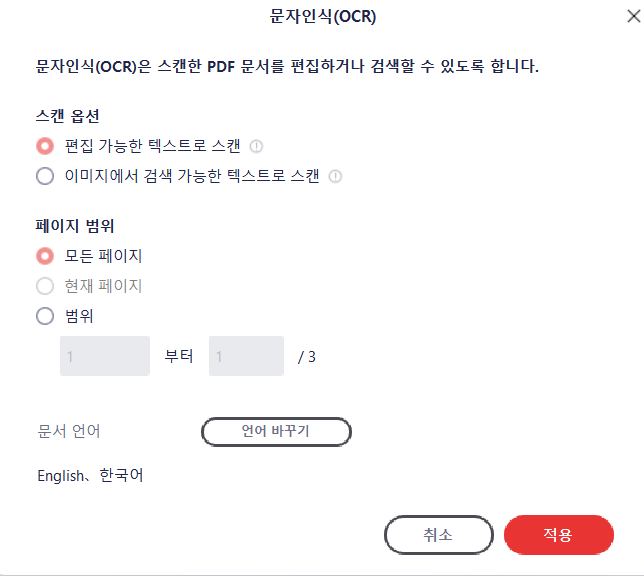
OCR시 옵션을 설정할 수 있는데, 저는 디폴트 값으로 적용해주었어요.
'편집 가능한 텍스트로 스캔'은 텍스트 자체가 OCR인식 된 내용으로 바뀌는 옵션이고,
'이미지에서 검색 가능한 텍스트로 스캔'은 겉보기에는 달라진 게 없는데 마우스로 긁으면(블록처리 하면) 텍스트 복사가 되는 옵션이에요.
둘 다 OCR 인식 결과 자체에는 차이가 없어요.

처리 중 표시가 뜨면 기다려줍니다.
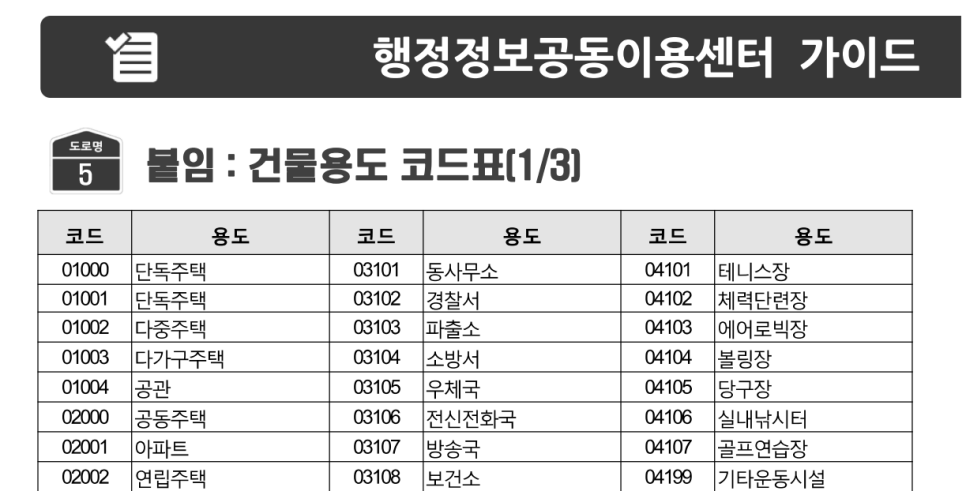
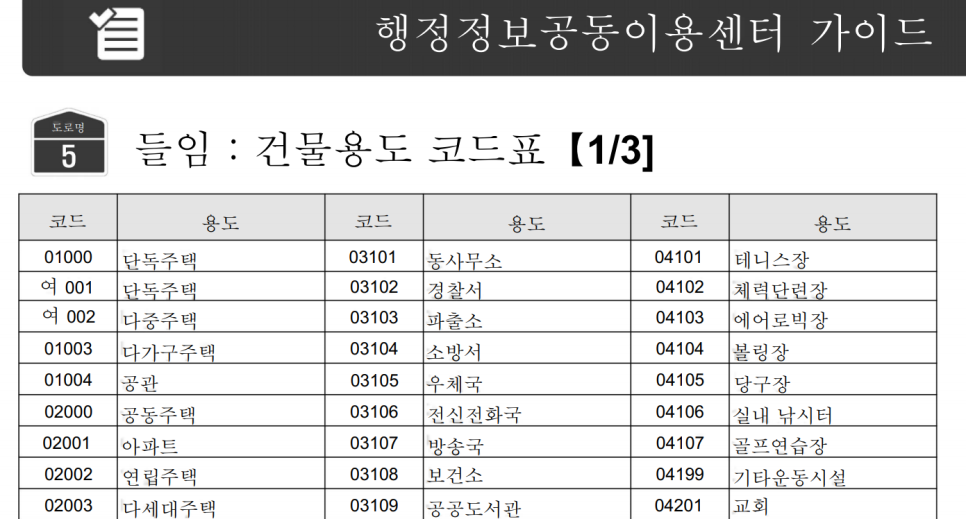
왼쪽이 원본이고, 오른쪽이 OCR 인식이 완료된 파일입니다.
가독성이 떨어지는 글씨체로 바뀐 것을 볼 수 있어요...!! ㅋㅋ 이러면 변환이 다 되었다는 뜻이에요.
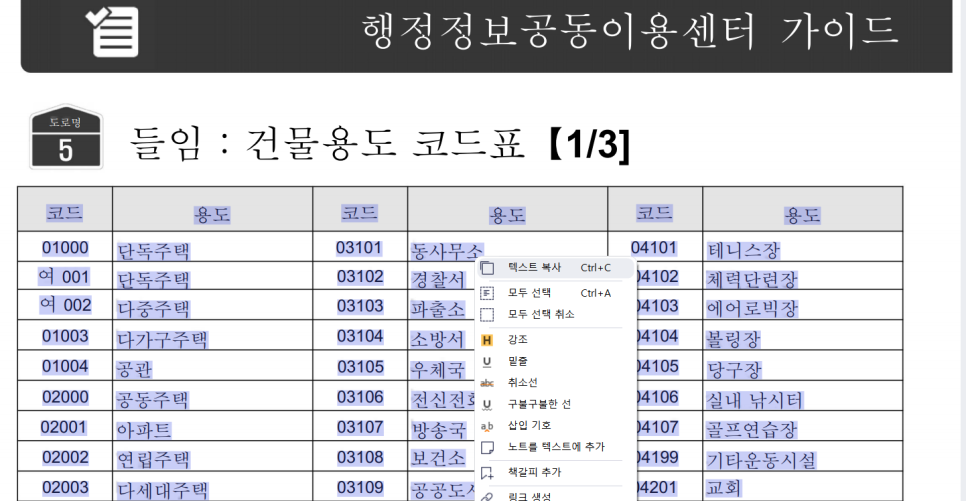
OCR 인식이 다 되었기 때문에 이렇게 복사도 가능해요.
물론 OCR 자체가 완벽한 것은 아니기 때문에 잘못 인식하기도 하는데요, 왼쪽의 단독주택을 보시면 01001이 여001로 인식된 것을 볼 수 있어요.
01이 여로 잘못 인식된 것입니다..!
완벽하지 않아 수정이 필요하긴 하지만 그래도 내가 전부다 일일이 손으로 치는 것보다는 낫죠 하하
위와 같이 복사를 눌러준 후 사용하고 싶은 곳에 붙여넣기 하면 됩니다.
만약 엑셀에 표의 형태로 넣고 싶은 분들을 다른 방법이 필요한데요, 이걸 그대로 엑셀에 붙여넣기 하면 아래와 같이 나와요.
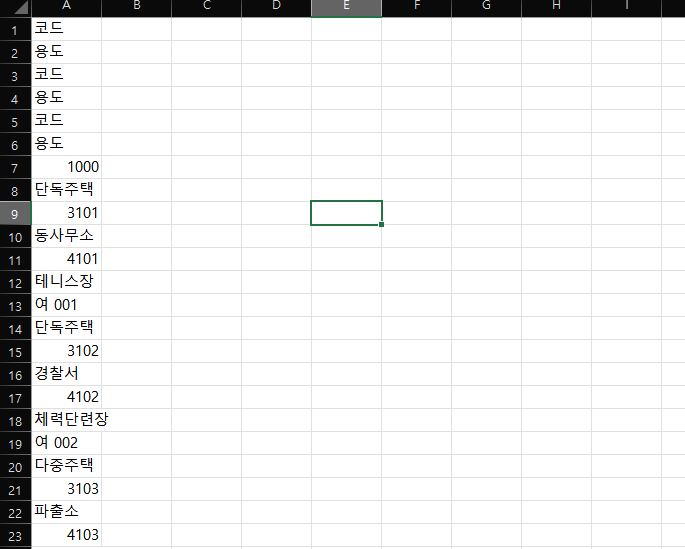
우리는 표의 형태가 필요하므로 다른 방법을 적용해봅시다.
먼저 OCR 인식된 파일을 다른이름으로 저장해주세요.
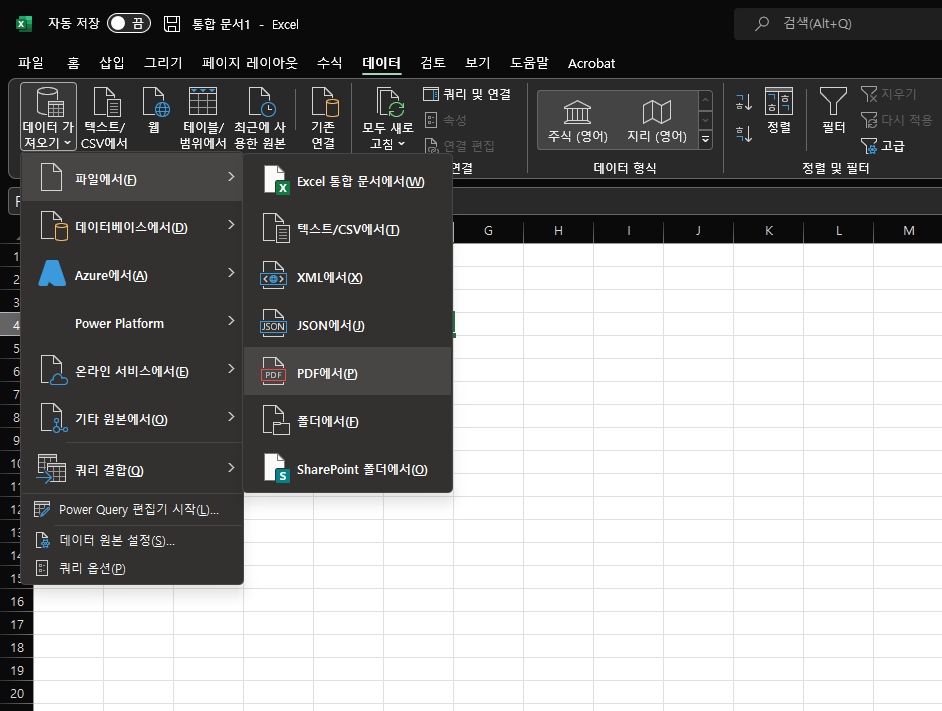
엑셀의 [데이터]탭 > [데이터 가져오기] > [파일에서] > [PDF에서] 누른 후 방금 저장한 OCR 파일을 불러옵니다.
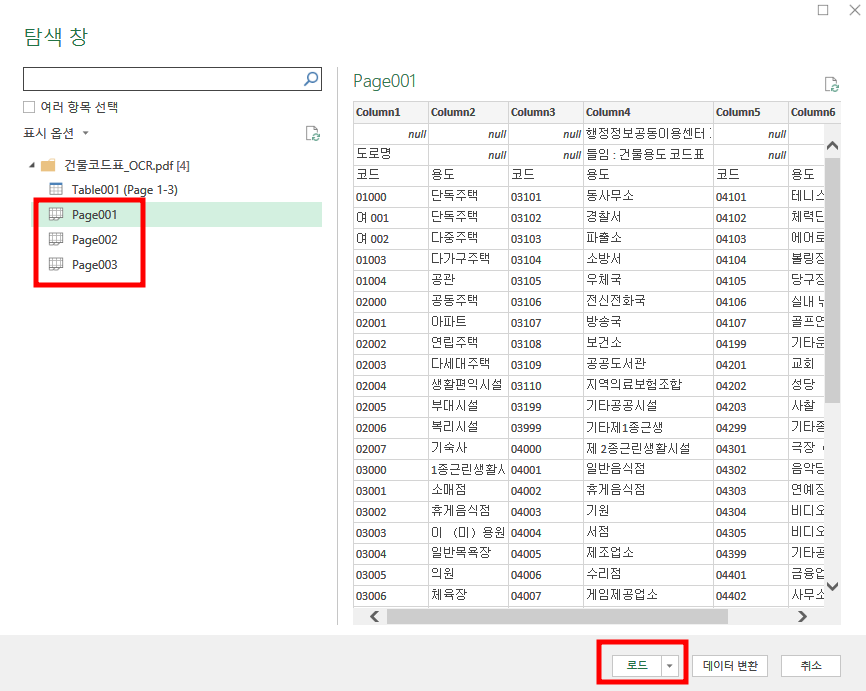
그럼 이와 같이 엑셀이 알아서 해당 PDF 속의 표들을 이렇게 찾아주는데요,
내가 넣고 싶은 표가 맞다면 '로드'를 누릅니다.
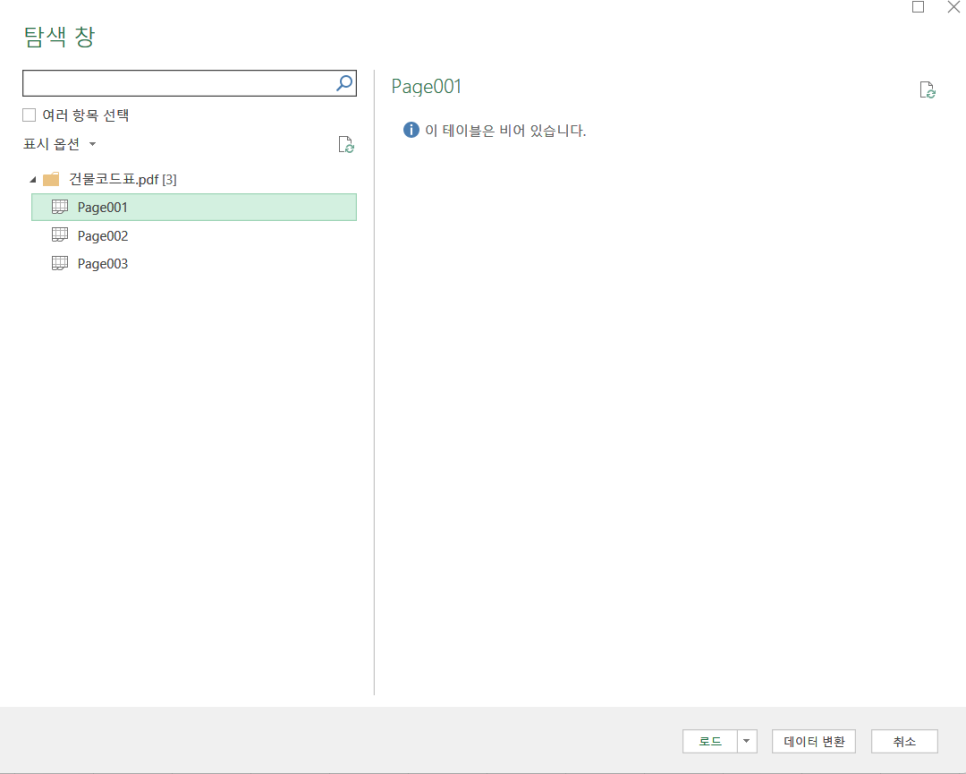
만약 우리가 OCR 인식을 하지 않았더라면, 아래와 같이 '이 테이블은 비어 있습니다'라고 나옵니다. 그러니 OCR은 필수!
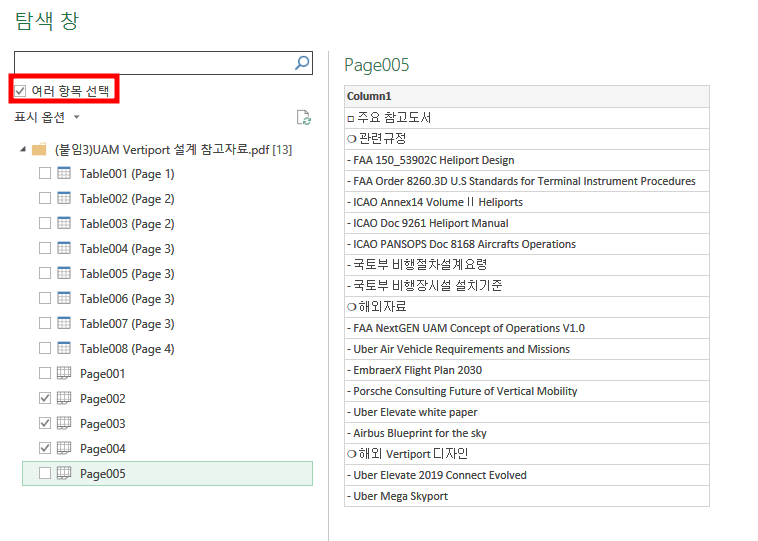
참고 : 만약 여러 개의 표를 넣고 싶다면 상단의 '여러 항목 선택' 클릭!
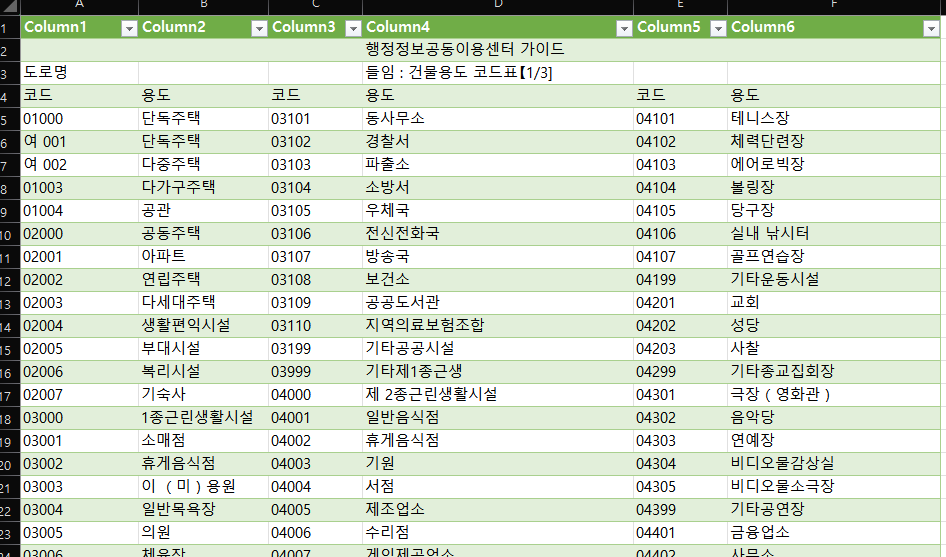
그럼 이렇게 표가 생성되는데요, 저는 불필요한 서식은 제거하기 위해
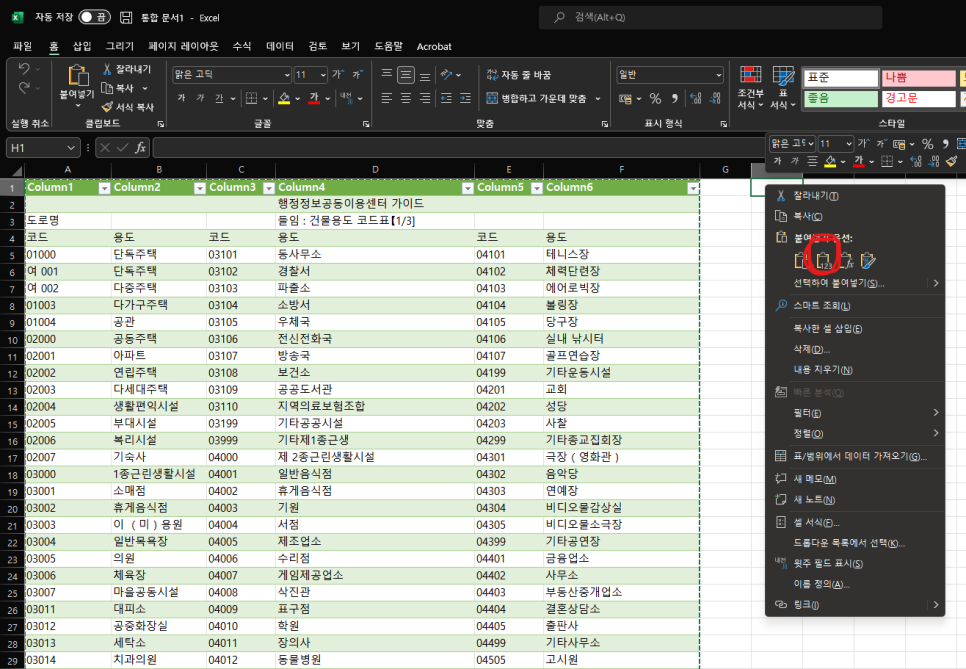
초록 표를 복사해서 옆에다 값으로 붙여넣기 해줍니다.
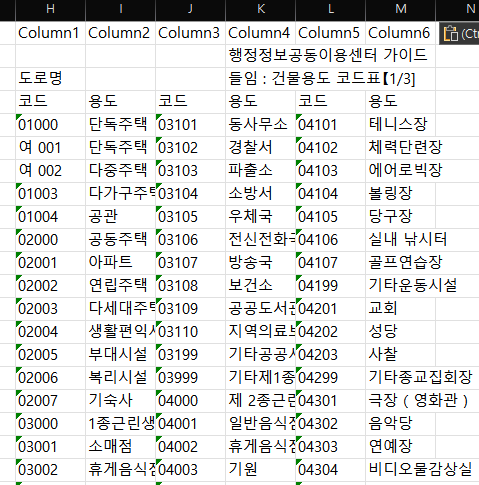
그럼 이렇게 붙여넣기 완성!
이제 잘못 인식된 글자를 고친 후 자유롭게 쓰면 됩니다 :)
그럼 20000!
'🖥️ IT, 컴퓨터 > 👩🏻💻 IT' 카테고리의 다른 글
| 상업 이용 가능한 일러스트/이미지 사이트 모음 (0) | 2023.03.23 |
|---|---|
| 하늘 합성하는 무료 어플 : Adobe PScamera (0) | 2023.03.23 |
| [생산성] AI가 코딩 해주는 사이트 (0) | 2023.03.17 |
| [Windows 11] 윈도우 11 한글 깨짐 해결방법 : 시스템 로캘 변경 (0) | 2023.03.14 |
| [IT] Gmail 구글메일 상대방의 읽음 여부/조회수 무료로 확인하는 방법 (0) | 2023.03.10 |

댓글