sf 및 tintygraph를 사용하는 R의 공간 네트워크
Lucas van der Meer, Robin Lovelace & Lorena Abad 2019년 9월 26일
소개
거리 네트워크, 운송 경로, 통신 라인, 강 유역. 공간 네트워크의 모든 예: 공간에 내장된 노드와 에지의 조직화된 시스템. 대부분의 경우 이러한 노드와 가장자리는 지리적 좌표와 연관될 수 있습니다. 즉, 노드는 지리적 점이고 가장자리는 지리적 선입니다.
이러한 공간 네트워크는 그래프 이론을 사용하여 분석할 수 있습니다. 그래프 이론과 네트워크 분석의 토대를 마련한 Leonhard Eulers의 유명한 Köningsberg의 Seven Bridges 작업은 본질적으로 공간 문제였습니다.
R에는 공간 데이터와 네트워크 분석을 위한 최신 도구가 있습니다. 또한 공간 네트워크 분석(일부)을 포함하는 여러 패키지가 개발되었습니다. 이 github 문제 와 이 트윗 에서 언급했듯이 공간 네트워크를 가장 잘 표현하고 분석하는 방법에 대한 합의는 어려운 것으로 판명되었습니다.
이 블로그 포스트는 일련의 지리적 선으로 시작하여 네트워크 분석에 사용할 준비가 된 객체로 이어지는 공간 네트워크에 대한 접근 방식을 보여줍니다. 그 과정에서 R에서 공간 네트워크를 분석하는 프로세스가 사용자 친화적이고 효율적이기 전에 취해야 할 단계가 여전히 있음을 알 수 있습니다.
공간 네트워크용 기존 R 패키지
R은 원래 통계 컴퓨팅을 위한 언어로 설계되었지만 활성 'R-공간' 생태계가 진화했습니다. 공간 데이터 분석을 위한 강력하고 고성능 패키지는 주로 sf 패키지에서 GDAL , GEOS 및 PROJ와 같은 성숙한 C/C++ 라이브러리에 대한 인터페이스 덕분에 개발되었습니다 . 마찬가지로, 그래프 표현 및 분석을 위한 많은 패키지가 개발되었으며, 특히 igraph 를 기반으로 하는 Tidygraph 가 있습니다 .
sf와 tintygraph 모두 tibble데이터 처리 파이프라인, 유형 안정성 및 모든 것을 데이터 프레임으로 나타내는 규칙( tibble사용자 친화적인 기본 설정이 있는 데이터 프레임인 a ). sf에서 이것은 공간 벡터 데이터를 class 의 객체로 저장하는 것을 의미합니다 sf. 이는 본질적으로 일반 데이터 프레임(또는 tibble)과 동일하지만 각 기능(행) 및 속성에 대한 지오메트리를 포함하는 추가 'sticky' 목록 열이 있습니다. 경계 상자 및 CRS와 같은. Tidygraph는 클래스의 객체에 네트워크를 저장합니다 tbl_graph. A tbl_graph는 igraph개체이지만 사용자가 가장자리와 노드 요소를 모두 데이터 프레임인 것처럼 조작할 수 있습니다.
sf와 tintygraph는 모두 비교적 새로운 패키지입니다(각각 2016년과 2017년에 CRAN에서 처음 출시됨). 따라서 공간 네트워크의 하이브리드, 티블 기반 표현을 허용하기 위해 아직 결합되지 않았다는 것은 놀라운 일이 아닙니다.
그럼에도 불구하고 공간 네트워크를 표현하기 위해 여러 접근 방식이 개발되었으며 그 중 일부는 CRAN에 게시된 패키지에 있습니다. 예를 들어 stplanr 에는 sp (2005년에 출시된 공간 데이터 분석용 패키지) 및 sf 패키지 SpatialLinesNetwork모두에서 작동하는 클래스 가 포함되어 있습니다. dodgr 은 방향 그래프(예: 일방 통행 거리를 나타내는 방향 종속 가중치를 가질 수 있음)에 중점을 둔 거리 네트워크용 분석 도구를 제공하는 최신 패키지입니다. R에서 공간 네트워크를 구현하려는 다른 패키지에는 sp와 igraph를 결합한 클래스 시스템을 정의한 패키지인 spnetwork 및 shp2graph 가 포함됩니다., sp와 igraph 객체 사이를 전환하는 도구를 제공합니다.
각 패키지에는 더 자세히 살펴볼 가치가 있는 장점이 있습니다(다음 블로그 게시물에서 가능). 이 게시물의 나머지 부분에서는 개체에서 개체 sf를 결합하는 접근 방식을 간략하게 설명 합니다.igraphtidygraph
설정
다음 코드 청크는 이 게시물에 사용된 패키지를 설치합니다.
# We'll use remotes to install packages, install it if needs be:
if(!"remotes" %in% installed.packages()) {
install.packages("remotes")
}
cran_pkgs = c(
"sf",
"tidygraph",
"igraph",
"osmdata",
"dplyr",
"tibble",
"ggplot2",
"units",
"tmap",
"rgrass7",
"link2GI",
"nabor"
)
remotes::install_cran(cran_pkgs)
library(sf)
library(tidygraph)
library(igraph)
library(dplyr)
library(tibble)
library(ggplot2)
library(units)
library(tmap)
library(osmdata)
library(rgrass7)
library(link2GI)
library(nabor)
데이터 가져오기
예를 들어 독일 뮌스터 도심의 도로망을 사용합니다. OpenStreetMap에서 데이터를 가져옵니다. 같은 패키지 dodgr 는 이러한 데이터에 대해 코드를 최적화했지만 모든 데이터 소스에 대해 이 워크플로를 보여주고자 한다는 점을 고려할 때 기하 도형 sf만 포함하는 클래스 개체를 생성합니다 LINESTRING. 그러나 루프를 형성하는 거리는 에서 osmdata선이 아닌 다각형으로 반환됩니다. osm_poly2line이것들은 함수 를 사용하여 라인으로 변환할 것 입니다. 하나의 추가 변수인 거리 유형이 추가되어 sf여러 추가 변수를 포함하는 개체에 대해 동일한 단계를 사용할 수 있음을 보여줍니다.
muenster <- opq(bbox = c(7.61, 51.954, 7.636, 51.968)) %>%
add_osm_feature(key = 'highway') %>%
osmdata_sf() %>%
osm_poly2line()
muenster_center <- muenster$osm_lines %>%
select(highway)
muenster_center
## Simple feature collection with 2233 features and 1 field
## geometry type: LINESTRING
## dimension: XY
## bbox: xmin: 7.603762 ymin: 51.94823 xmax: 7.641418 ymax: 51.97241
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## First 10 features:
## highway geometry
## 4064462 primary LINESTRING (7.624554 51.955...
## 4064463 primary LINESTRING (7.626498 51.956...
## 4064467 residential LINESTRING (7.630898 51.955...
## 4064474 primary LINESTRING (7.61972 51.9554...
## 4064476 primary LINESTRING (7.619844 51.954...
## 4064482 tertiary LINESTRING (7.616395 51.957...
## 4064485 service LINESTRING (7.63275 51.9603...
## 4984982 secondary LINESTRING (7.614156 51.967...
## 4985138 cycleway LINESTRING (7.61525 51.9673...
## 4985140 residential LINESTRING (7.616774 51.968...
ggplot(data = muenster_center) + geom_sf()
sf에서 tbl_graph로: 단계적 접근
1단계: 네트워크 정리
네트워크 분석을 수행하려면 깨끗한 토폴로지를 가진 네트워크가 필요합니다. 이론적으로 네트워크 토폴로지를 정리하는 가장 좋은 방법은 수동 편집이지만, 이는 주로 대규모 네트워크의 경우 매우 노동 집약적이고 시간이 많이 소요될 수 있습니다. GRASS GIS 소프트웨어 의 v.clean 도구 세트는 이 작업을 위한 자동화된 기능을 제공하므로 공간 네트워크 분석 분야에서 널리 사용되는 도구입니다. 우리가 아는 한, 이 도구 세트에 상응하는 R은 없지만 다행히도 rgrass7 및 link2GI 패키지를 사용하면 GRASS GIS에 쉽게 '연결'할 수 있습니다. 분명히 이것은 컴퓨터에 GRASS GIS가 설치되어 있어야 합니다. R을 오픈 소스 GIS 소프트웨어와 결합하는 방법에 대한 자세한 설명은 9장 을 참조하십시오.R과 Geocomputation의 연결. 특히 Windows 운영 체제에서 연결 프로세스에 시간이 걸릴 수 있음을 고려하십시오. rgrass7 또한 최근에 패키지 가 크게 변경 되어 sf. 그러나 이는 이전 버전의 을 사용하는 경우 아래 코드가 작동하지 않는다는 의미이기도 rgrass7하므로 필요한 경우 업데이트해야 합니다.
여기에서 교차로에서 선을 끊고 접힌 루프를 형성하는 선을 끊음으로써 네트워크 토폴로지를 정리합니다. 그러면 중복된 지오메트리 기능이 제거됩니다. 완료되면 데이터를 다시 R로 읽고 기하학 이 있는 sf 객체 로 다시 변환합니다. 이를 위해 이 게시물 의 소스 코드 에서 볼 수 있는 일부 설정 코드가 필요한 rgrass7LINESTRING 을 사용 합니다.
# Add data to GRASS spatial database
writeVECT(
SDF = muenster_center,
vname = 'muenster_center',
v.in.ogr_flags = 'overwrite'
)
# Execute the v.clean tool
execGRASS("g.proj", flags = c("c", "quiet"), proj4 = proj4)
execGRASS(
cmd = 'v.clean',
input = 'muenster_center',
output = 'muenster_cleaned',
tool = 'break',
flags = c('overwrite', 'c')
)
# Read back into R
use_sf()
muenster_center <- readVECT('muenster_cleaned') %>%
rename(geometry = geom) %>%
select(-cat)
muenster_center
## Simple feature collection with 4667 features and 1 field
## geometry type: LINESTRING
## dimension: XY
## bbox: xmin: 7.603762 ymin: 51.94823 xmax: 7.641418 ymax: 51.97241
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## First 10 features:
## highway geometry
## 1 service LINESTRING (7.63275 51.9603...
## 2 secondary LINESTRING (7.614156 51.967...
## 3 cycleway LINESTRING (7.61525 51.9673...
## 4 footway LINESTRING (7.629304 51.967...
## 5 steps LINESTRING (7.627696 51.965...
## 6 service LINESTRING (7.633612 51.965...
## 7 residential LINESTRING (7.630564 51.957...
## 8 service LINESTRING (7.613545 51.960...
## 9 cycleway LINESTRING (7.619781 51.957...
## 10 residential LINESTRING (7.62373 51.9643...
2단계: 각 가장자리에 고유한 인덱스 제공
네트워크의 가장자리는 단순히 데이터의 선스트링입니다. 그들 각각은 나중에 시작 및 끝 노드와 관련될 수 있는 고유 인덱스를 얻습니다.
edges <- muenster_center %>%
mutate(edgeID = c(1:n()))
edges
## Simple feature collection with 4667 features and 2 fields
## geometry type: LINESTRING
## dimension: XY
## bbox: xmin: 7.603762 ymin: 51.94823 xmax: 7.641418 ymax: 51.97241
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## First 10 features:
## highway geometry edgeID
## 1 service LINESTRING (7.63275 51.9603... 1
## 2 secondary LINESTRING (7.614156 51.967... 2
## 3 cycleway LINESTRING (7.61525 51.9673... 3
## 4 footway LINESTRING (7.629304 51.967... 4
## 5 steps LINESTRING (7.627696 51.965... 5
## 6 service LINESTRING (7.633612 51.965... 6
## 7 residential LINESTRING (7.630564 51.957... 7
## 8 service LINESTRING (7.613545 51.960... 8
## 9 cycleway LINESTRING (7.619781 51.957... 9
## 10 residential LINESTRING (7.62373 51.9643... 10
3단계: 각 모서리의 시작점과 끝점에 노드 생성
네트워크의 노드는 가장자리의 시작점과 끝점입니다. 이러한 점의 위치는 st_coordinates sf의 함수를 사용하여 파생될 수 있습니다. 일련의 라인스트링이 주어지면 이 함수는 라인스트링을 구성하는 포인트로 각 라인스트링을 분해합니다. 해당 점의 X 및 Y 좌표와 추가로 점이 속하는 선을 지정하는 정수 표시기 L1이 있는 행렬을 반환합니다. 이 정수 표시기는 1단계에서 정의한 에지 인덱스에 해당합니다. 즉, 행렬을 a data.frame또는 로 변환 tibble하고 에지 인덱스로 기능을 그룹화하고 각 그룹의 첫 번째 및 마지막 기능만 유지하면 시작과 라인스트링의 끝점.
nodes <- edges %>%
st_coordinates() %>%
as_tibble() %>%
rename(edgeID = L1) %>%
group_by(edgeID) %>%
slice(c(1, n())) %>%
ungroup() %>%
mutate(start_end = rep(c('start', 'end'), times = n()/2))
nodes
## # A tibble: 9,334 x 4
## X Y edgeID start_end
## <dbl> <dbl> <dbl> <chr>
## 1 7.63 52.0 1 start
## 2 7.63 52.0 1 end
## 3 7.61 52.0 2 start
## 4 7.61 52.0 2 end
## 5 7.62 52.0 3 start
## 6 7.62 52.0 3 end
## 7 7.63 52.0 4 start
## 8 7.63 52.0 4 end
## 9 7.63 52.0 5 start
## 10 7.63 52.0 5 end
## # … with 9,324 more rows
4단계: 각 노드에 고유한 인덱스 제공
네트워크의 각 노드는 에지와 관련될 수 있도록 고유한 인덱스를 가져와야 합니다. 그러나 모서리가 시작점 및/또는 끝점을 공유할 수 있다는 점을 고려해야 합니다. 동일한 X 및 Y 좌표를 갖는 이러한 중복 점은 하나의 단일 노드이므로 동일한 인덱스를 가져와야 합니다. Tibble에 표시되는 좌표 값은 반올림되며 그렇지 않은 경우에도 여러 행에서 동일하게 보일 수 있습니다. dplyr의 함수를 사용하여 group_indices 고유한 X,Y 조합의 각 그룹에 고유한 인덱스를 제공할 수 있습니다.
nodes <- nodes %>%
mutate(xy = paste(.$X, .$Y)) %>%
mutate(nodeID = group_indices(., factor(xy, levels = unique(xy)))) %>%
select(-xy)
nodes
## # A tibble: 9,334 x 5
## X Y edgeID start_end nodeID
## <dbl> <dbl> <dbl> <chr> <int>
## 1 7.63 52.0 1 start 1
## 2 7.63 52.0 1 end 2
## 3 7.61 52.0 2 start 3
## 4 7.61 52.0 2 end 4
## 5 7.62 52.0 3 start 5
## 6 7.62 52.0 3 end 6
## 7 7.63 52.0 4 start 7
## 8 7.63 52.0 4 end 8
## 9 7.63 52.0 5 start 9
## 10 7.63 52.0 5 end 10
## # … with 9,324 more rows
5단계: 노드 인덱스를 가장자리와 결합
이제 4단계에서 각 시작점과 끝점에 노드 ID가 할당되었으므로 노드 인덱스를 가장자리에 추가할 수 있습니다. 즉, 각 에지에 대해 시작하는 노드와 끝나는 노드를 지정할 수 있습니다.
source_nodes <- nodes %>%
filter(start_end == 'start') %>%
pull(nodeID)
target_nodes <- nodes %>%
filter(start_end == 'end') %>%
pull(nodeID)
edges = edges %>%
mutate(from = source_nodes, to = target_nodes)
edges
## Simple feature collection with 4667 features and 4 fields
## geometry type: LINESTRING
## dimension: XY
## bbox: xmin: 7.603762 ymin: 51.94823 xmax: 7.641418 ymax: 51.97241
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## First 10 features:
## highway geometry edgeID from to
## 1 service LINESTRING (7.63275 51.9603... 1 1 2
## 2 secondary LINESTRING (7.614156 51.967... 2 3 4
## 3 cycleway LINESTRING (7.61525 51.9673... 3 5 6
## 4 footway LINESTRING (7.629304 51.967... 4 7 8
## 5 steps LINESTRING (7.627696 51.965... 5 9 10
## 6 service LINESTRING (7.633612 51.965... 6 11 12
## 7 residential LINESTRING (7.630564 51.957... 7 13 14
## 8 service LINESTRING (7.613545 51.960... 8 15 16
## 9 cycleway LINESTRING (7.619781 51.957... 9 17 18
## 10 residential LINESTRING (7.62373 51.9643... 10 19 20
6단계: 중복 노드 제거
에지 데이터에 고유한 노드 ID를 추가하면 더 이상 복제된 시작 및 끝점이 필요하지 않습니다. 그것들을 제거한 후에는 tibble각 행이 고유한 단일 노드를 나타내는 것으로 끝납니다. sf이 tibble은 형상이 있는 개체 로 변환될 수 있습니다 POINT.
nodes <- nodes %>%
distinct(nodeID, .keep_all = TRUE) %>%
select(-c(edgeID, start_end)) %>%
st_as_sf(coords = c('X', 'Y')) %>%
st_set_crs(st_crs(edges))
nodes
## Simple feature collection with 3329 features and 1 field
## geometry type: POINT
## dimension: XY
## bbox: xmin: 7.603762 ymin: 51.94823 xmax: 7.641418 ymax: 51.97241
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## # A tibble: 3,329 x 2
## nodeID geometry
## <int> <POINT [°]>
## 1 1 (7.63275 51.9603)
## 2 2 (7.631843 51.96061)
## 3 3 (7.614156 51.96724)
## 4 4 (7.613797 51.96723)
## 5 5 (7.61525 51.96736)
## 6 6 (7.615148 51.96745)
## 7 7 (7.629304 51.96712)
## 8 8 (7.629308 51.9673)
## 9 9 (7.627696 51.96534)
## 10 10 (7.62765 51.96534)
## # … with 3,319 more rows
7단계: tbl_graph로 변환
처음 6단계 에서는 네트워크의 가장자리를 나타내는 기하 도형이 있는 개체 하나 sf와 네트워크의 노드를 나타내는 도형이 있는 개체 하나가 생성되었습니다. 이 기능을 사용하면 이 두 가지를 객체 로 변환할 수 있습니다 . 이 단계에서 강조해야 할 두 가지 까다로운 부분이 있습니다. 하나는 소스 및 대상 노드의 인덱스를 포함하는 열이 개체의 처음 두 열이거나 각각 'to' 및 'from'으로 이름이 지정되어야 한다는 것입니다. 둘째, 함수 내에서 이러한 열은 2열 행렬로 변환됩니다. 그러나LINESTRINGsfPOINTtbl_graphtbl_graphsftbl_graphsf객체에는 특정 열이 선택될 때마다 지오메트리 열이 속성에 고정된다는 것을 의미하는 소위 '고정 기하학'이 있습니다. 따라서 내부 tbl_graph에 생성된 행렬에는 2개가 아닌 3개의 열이 있으며 오류가 발생합니다. 따라서 를 생성하기 전에 먼저 sf객체를 일반 data.frame또는 로 변환해야 합니다 . 결국 노드와 에지 모두 구조에 '통합'되고 고유한 특성 이 느슨해지기 때문에 이것은 중요하지 않습니다.tibbletbl_graphigraphsf
graph = tbl_graph(nodes = nodes, edges = as_tibble(edges), directed = FALSE)
graph
## # A tbl_graph: 3329 nodes and 4667 edges
## #
## # An undirected multigraph with 34 components
## #
## # Node Data: 3,329 x 2 (active)
## nodeID geometry
## <int> <POINT [°]>
## 1 1 (7.63275 51.9603)
## 2 2 (7.631843 51.96061)
## 3 3 (7.614156 51.96724)
## 4 4 (7.613797 51.96723)
## 5 5 (7.61525 51.96736)
## 6 6 (7.615148 51.96745)
## # … with 3,323 more rows
## #
## # Edge Data: 4,667 x 5
## from to highway geometry edgeID
## <int> <int> <fct> <LINESTRING [°]> <int>
## 1 1 2 service (7.63275 51.9603, 7.631843 51.96061) 1
## 2 3 4 secondary (7.614156 51.96724, 7.613797 51.96723) 2
## 3 5 6 cycleway (7.61525 51.96736, 7.615165 51.96744, 7.615… 3
## # … with 4,664 more rows
8단계: 합치기
접근 방식을 보다 편리하게 만들기 위해 위의 모든 단계를 단일 함수로 결합할 수 있습니다. 이 함수는 기하 도형이 포함된 정리된 sf개체를 LINESTRING입력으로 사용하고 spatial 을 반환합니다 tbl_graph.
sf_to_tidygraph = function(x, directed = TRUE) {
edges <- x %>%
mutate(edgeID = c(1:n()))
nodes <- edges %>%
st_coordinates() %>%
as_tibble() %>%
rename(edgeID = L1) %>%
group_by(edgeID) %>%
slice(c(1, n())) %>%
ungroup() %>%
mutate(start_end = rep(c('start', 'end'), times = n()/2)) %>%
mutate(xy = paste(.$X, .$Y)) %>%
mutate(nodeID = group_indices(., factor(xy, levels = unique(xy)))) %>%
select(-xy)
source_nodes <- nodes %>%
filter(start_end == 'start') %>%
pull(nodeID)
target_nodes <- nodes %>%
filter(start_end == 'end') %>%
pull(nodeID)
edges = edges %>%
mutate(from = source_nodes, to = target_nodes)
nodes <- nodes %>%
distinct(nodeID, .keep_all = TRUE) %>%
select(-c(edgeID, start_end)) %>%
st_as_sf(coords = c('X', 'Y')) %>%
st_set_crs(st_crs(edges))
tbl_graph(nodes = nodes, edges = as_tibble(edges), directed = directed)
}
sf_to_tidygraph(muenster_center, directed = FALSE)
## # A tbl_graph: 3329 nodes and 4667 edges
## #
## # An undirected multigraph with 34 components
## #
## # Node Data: 3,329 x 2 (active)
## nodeID geometry
## <int> <POINT [°]>
## 1 1 (7.63275 51.9603)
## 2 2 (7.631843 51.96061)
## 3 3 (7.614156 51.96724)
## 4 4 (7.613797 51.96723)
## 5 5 (7.61525 51.96736)
## 6 6 (7.615148 51.96745)
## # … with 3,323 more rows
## #
## # Edge Data: 4,667 x 5
## from to highway geometry edgeID
## <int> <int> <fct> <LINESTRING [°]> <int>
## 1 1 2 service (7.63275 51.9603, 7.631843 51.96061) 1
## 2 3 4 secondary (7.614156 51.96724, 7.613797 51.96723) 2
## 3 5 6 cycleway (7.61525 51.96736, 7.615165 51.96744, 7.615… 3
## # … with 4,664 more rows
두 세계의 장점을 결합
네트워크가 tbl_graph 구조에 저장되고 가장자리와 노드 모두에 대한 지오메트리 목록 열이 있으면 sf 및 tintygraph의 광범위한 기능을 깔끔한 공간에 깔끔하게 맞는 방식으로 결합할 수 있습니다.
동사를 사용 activate()하여 가장자리 또는 노드를 조작할지 여부를 지정합니다. 그러면 대부분의 dplyr 동사를 친숙한 방식으로 사용할 수 있으며 기하학 목록 열에 직접 적용할 때도 마찬가지입니다. 예를 들어, 각 모서리의 길이를 설명하는 변수를 추가할 수 있습니다. 이 변수는 나중에 모서리의 가중치로 사용됩니다.
graph <- graph %>%
activate(edges) %>%
mutate(length = st_length(geometry))
graph
## # A tbl_graph: 3329 nodes and 4667 edges
## #
## # An undirected multigraph with 34 components
## #
## # Edge Data: 4,667 x 6 (active)
## from to highway geometry edgeID length
## <int> <int> <fct> <LINESTRING [°]> <int> [m]
## 1 1 2 service (7.63275 51.9603, 7.631843 51.96061) 1 71.2778…
## 2 3 4 seconda… (7.614156 51.96724, 7.613797 51.967… 2 24.7146…
## 3 5 6 cycleway (7.61525 51.96736, 7.615165 51.9674… 3 12.2303…
## 4 7 8 footway (7.629304 51.96712, 7.629304 51.967… 4 20.0122…
## 5 9 10 steps (7.627696 51.96534, 7.62765 51.9653… 5 3.2926…
## 6 11 12 service (7.633612 51.96548, 7.633578 51.965… 6 7.4291…
## # … with 4,661 more rows
## #
## # Node Data: 3,329 x 2
## nodeID geometry
## <int> <POINT [°]>
## 1 1 (7.63275 51.9603)
## 2 2 (7.631843 51.96061)
## 3 3 (7.614156 51.96724)
## # … with 3,326 more rows
하나의 파이프 흐름으로 그래프 구조를 '이스케이프'하고, 가장자리 또는 노드를 다시 실제 sf개체로 전환하고, 예를 들어 특정 변수를 기반으로 데이터를 요약할 수 있습니다.
graph %>%
activate(edges) %>%
as_tibble() %>%
st_as_sf() %>%
group_by(highway) %>%
summarise(length = sum(length))
## Simple feature collection with 17 features and 2 fields
## geometry type: MULTILINESTRING
## dimension: XY
## bbox: xmin: 7.603762 ymin: 51.94823 xmax: 7.641418 ymax: 51.97241
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## # A tibble: 17 x 3
## highway length geometry
## * <fct> [m] <MULTILINESTRING [°]>
## 1 corridor 9.377… ((7.620506 51.96262, 7.620542 51.96266), (7.6205…
## 2 cycleway 19275.917… ((7.619683 51.95395, 7.619641 51.95378, 7.619559…
## 3 footway 42822.070… ((7.640529 51.95325, 7.640528 51.95323, 7.640531…
## 4 path 8193.341… ((7.624007 51.95379, 7.624223 51.95378, 7.624253…
## 5 pedestrian 11399.337… ((7.620362 51.95471, 7.620477 51.9547), (7.62012…
## 6 primary 3574.842… ((7.625556 51.95272, 7.625594 51.95284, 7.625714…
## 7 primary_li… 184.385… ((7.617285 51.96609, 7.617286 51.96624, 7.617295…
## 8 residential 22729.748… ((7.614509 51.95351, 7.614554 51.95346), (7.6230…
## 9 secondary 4460.683… ((7.629784 51.95446, 7.629842 51.95444), (7.6312…
## 10 secondary_… 160.708… ((7.635309 51.95946, 7.635705 51.95948), (7.6349…
## 11 service 27027.822… ((7.624803 51.95393, 7.625072 51.95393), (7.6158…
## 12 steps 1321.841… ((7.634423 51.9546, 7.634438 51.95462), (7.61430…
## 13 tertiary 4356.365… ((7.607112 51.94991, 7.607126 51.94992, 7.607183…
## 14 tertiary_l… 43.856… ((7.623592 51.96612, 7.623568 51.96611, 7.623468…
## 15 track 389.866… ((7.610671 51.95778, 7.610571 51.95759, 7.610585…
## 16 unclassifi… 612.816… ((7.634492 51.95613, 7.634689 51.95611), (7.6343…
## 17 <NA> 3161.883… ((7.634374 51.95579, 7.634545 51.95575, 7.634662…
객체로 다시 전환 sf하는 것은 공간 속성을 유지하는 방식으로 네트워크를 플로팅할 때도 유용합니다.
ggplot() +
geom_sf(data = graph %>% activate(edges) %>% as_tibble() %>% st_as_sf()) +
geom_sf(data = graph %>% activate(nodes) %>% as_tibble() %>% st_as_sf(), size = 0.5)

또는 몇 줄의 코드로 네트워크를 대화형 맵으로 플로팅합니다. 이 페이지에서는 대화형 지도가 이미지로 표시될 수 있지만 여기 에서는 실제로 상호 작용할 수 있어야 합니다.
tmap_mode('view')
tm_shape(graph %>% activate(edges) %>% as_tibble() %>% st_as_sf()) +
tm_lines() +
tm_shape(graph %>% activate(nodes) %>% as_tibble() %>% st_as_sf()) +
tm_dots() +
tmap_options(basemaps = 'OpenStreetMap')

모두 훌륭하지만 그래프 표현이 반드시 필요한 것은 아닙니다. Tidygraph의 부가 가치는 네트워크 분석을 위해 특별히 설계된 igraph 라이브러리의 기능에 대한 문을 열어주고 '정리한' 워크플로 내에서 사용할 수 있도록 한다는 것입니다. 그것들을 모두 다루려면 책을 써야 하지만 최소한 아래에 몇 가지 예를 보여 드리겠습니다.
중심성 대책
중심성 측정은 네트워크에서 노드의 중요성을 설명합니다. 이러한 측정 중 가장 간단한 것은 정도 중심성(노드에 연결된 가장자리의 수)입니다. 또 다른 예는 간단히 말해서 노드를 통과하는 최단 경로의 수인 매개 중심성입니다. Tidygraph에서 우리는 이들 및 다른 많은 중심성 측정을 계산할 수 있고 단순히 노드에 변수로 추가할 수 있습니다.
경계 중심성은 모서리에 대해서도 계산할 수 있습니다. 이 경우 가장자리를 통과하는 최단 경로의 수를 지정합니다.
graph <- graph %>%
activate(nodes) %>%
mutate(degree = centrality_degree()) %>%
mutate(betweenness = centrality_betweenness(weights = length)) %>%
activate(edges) %>%
mutate(betweenness = centrality_edge_betweenness(weights = length))
graph
## # A tbl_graph: 3329 nodes and 4667 edges
## #
## # An undirected multigraph with 34 components
## #
## # Edge Data: 4,667 x 7 (active)
## from to highway geometry edgeID length betweenness
## <int> <int> <fct> <LINESTRING [°]> <int> [m] <dbl>
## 1 1 2 service (7.63275 51.9603, 7.6318… 1 71.2778… 90271
## 2 3 4 second… (7.614156 51.96724, 7.61… 2 24.7146… 32946
## 3 5 6 cyclew… (7.61525 51.96736, 7.615… 3 12.2303… 12409
## 4 7 8 footway (7.629304 51.96712, 7.62… 4 20.0122… 22043
## 5 9 10 steps (7.627696 51.96534, 7.62… 5 3.2926… 83380
## 6 11 12 service (7.633612 51.96548, 7.63… 6 7.4291… 17119
## # … with 4,661 more rows
## #
## # Node Data: 3,329 x 4
## nodeID geometry degree betweenness
## <int> <POINT [°]> <dbl> <dbl>
## 1 1 (7.63275 51.9603) 3 117041
## 2 2 (7.631843 51.96061) 3 94899
## 3 3 (7.614156 51.96724) 3 32881
## # … with 3,326 more rows
ggplot() +
geom_sf(data = graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), col = 'grey50') +
geom_sf(data = graph %>% activate(nodes) %>% as_tibble() %>% st_as_sf(), aes(col = betweenness, size = betweenness)) +
scale_colour_viridis_c(option = 'inferno') +
scale_size_continuous(range = c(0,4))
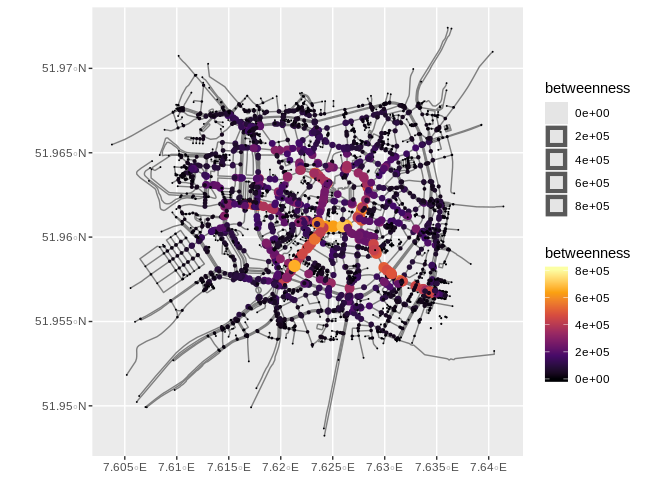
ggplot() +
geom_sf(data = graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), aes(col = betweenness, size = betweenness)) +
scale_colour_viridis_c(option = 'inferno') +
scale_size_continuous(range = c(0,4))

최단 경로
공간 네트워크 분석의 핵심 부분은 일반적으로 이동 거리나 이동 시간을 최소화하는 두 노드 사이의 경로를 찾는 것입니다. igraph에는 이를 위해 사용할 수 있는 여러 함수가 있으며, tbl_graph이는 객체의 하위 클래스일 뿐이 igraph 므로 igraph 패키지의 모든 함수에 직접 입력할 수 있습니다.
예를 들어, 함수 distances는 가능한 모든 노드 조합 사이의 최단 경로 거리를 포함하는 숫자 행렬을 반환합니다. 이러한 최단 경로를 계산하는 데 적합한 알고리즘을 자동으로 선택합니다.
distances <- distances(
graph = graph,
weights = graph %>% activate(edges) %>% pull(length)
)
distances[1:5, 1:5]
## [,1] [,2] [,3] [,4] [,5]
## [1,] 0.00000 71.27789 1670.22046 1694.9351 1596.80669
## [2,] 71.27789 0.00000 1619.80567 1644.5203 1546.39190
## [3,] 1670.22046 1619.80567 0.00000 24.7146 77.64829
## [4,] 1694.93506 1644.52027 24.71460 0.0000 102.36289
## [5,] 1596.80669 1546.39190 77.64829 102.3629 0.00000
'shortest_paths' 함수는 거리뿐만 아니라 경로를 구성하는 노드와 모서리의 인덱스도 반환합니다. 그것들을 대응하는 기하학 열과 연관시킬 때, 우리는 최단 경로의 공간적 표현을 얻습니다. 가능한 모든 노드 조합에 대해 이 작업을 수행하는 대신 최단 경로를 계산하려는 노드의 시작과 끝을 지정할 수 있습니다. 여기에서는 한 노드에서 다른 노드로 가는 최단 경로의 예를 보여주지만 일대다, 다대일 또는 다대다 노드에 대해 동일한 작업을 수행하는 것도 가능합니다. 그래프에 가중치가 부여될 때마다 Dijkstra 알고리즘이 후드 아래에서 사용됩니다. 여기서 원하는 출력을 미리 정의해야 합니다. vpath즉, 노드(igraph에서 꼭짓점이라고 함)만 반환되고 epath, 가장자리만 반환되며,both둘 다 반환합니다.
from_node <- graph %>%
activate(nodes) %>%
filter(nodeID == 3044) %>%
pull(nodeID)
to_node <- graph %>%
activate(nodes) %>%
filter(nodeID == 3282) %>%
pull(nodeID)
path <- shortest_paths(
graph = graph,
from = from_node,
to = to_node,
output = 'both',
weights = graph %>% activate(edges) %>% pull(length)
)
path$vpath
## [[1]]
## + 50/3329 vertices, from 2ee524d:
## [1] 3044 3043 1581 1076 1059 1058 1270 1489 609 608 1549 1550 2998 2448
## [15] 2057 1528 1529 1530 1531 1532 1533 1534 1535 1536 1537 1538 1539 1468
## [29] 1469 1470 1471 1704 1916 1476 23 24 3064 740 743 1053 1490 1447
## [43] 1446 1445 3052 1444 1443 3051 1442 3282
path$epath
## [[1]]
## + 49/4667 edges from 2ee524d:
## [1] 3043--3044 1581--3043 1076--1581 1059--1076 1058--1059 1058--1270
## [7] 1270--1489 609--1489 608-- 609 608--1549 1549--1550 1550--2998
## [13] 2448--2998 2057--2448 1528--2057 1528--1529 1529--1530 1530--1531
## [19] 1531--1532 1532--1533 1533--1534 1534--1535 1535--1536 1536--1537
## [25] 1537--1538 1538--1539 1468--1539 1468--1469 1469--1470 1470--1471
## [31] 1471--1704 1704--1916 1476--1916 23--1476 23-- 24 24--3064
## [37] 740--3064 740-- 743 743--1053 1053--1490 1447--1490 1446--1447
## [43] 1445--1446 1445--3052 1444--3052 1443--1444 1443--3051 1442--3051
## [49] 1442--3282
계산된 경로의 일부인 노드와 모서리만 포함하는 원래 그래프의 하위 그래프를 생성할 수 있습니다. 여기서 불편한 일이 발생합니다. igraph인덱스를 노드에 연결하기 위한 자체 기본 구조가 있는 것 같습니다. 이로 인해 egdes 데이터의 from및 to열이 더 이상 노드 데이터의 열과 일치하지 않고 nodeID대신 단순히 행을 참조합니다. 노드 데이터의 수.
path_graph <- graph %>%
subgraph.edges(eids = path$epath %>% unlist()) %>%
as_tbl_graph()
path_graph
## # A tbl_graph: 50 nodes and 49 edges
## #
## # An undirected simple graph with 1 component
## #
## # Node Data: 50 x 4 (active)
## nodeID geometry degree betweenness
## <int> <POINT [°]> <dbl> <dbl>
## 1 23 (7.62837 51.96292) 4 425585
## 2 24 (7.628317 51.96308) 3 499622
## 3 608 (7.626629 51.95707) 3 196573
## 4 609 (7.626621 51.95699) 3 390732
## 5 740 (7.629458 51.96364) 3 158948
## 6 743 (7.629787 51.96392) 3 156575
## # … with 44 more rows
## #
## # Edge Data: 49 x 7
## from to highway geometry edgeID length betweenness
## <int> <int> <fct> <LINESTRING [°]> <int> [m] <dbl>
## 1 1 2 reside… (7.62837 51.96292, 7.628… 12 18.6254… 426879
## 2 3 4 reside… (7.626629 51.95707, 7.62… 355 8.2067… 198070
## 3 8 9 reside… (7.626552 51.95648, 7.62… 643 6.5847… 149777
## # … with 46 more rows
이 하위 그래프는 이제 예를 들어 경로의 총 길이를 계산하여 분석할 수 있습니다.
path_graph %>%
activate(edges) %>%
as_tibble() %>%
summarise(length = sum(length))
## # A tibble: 1 x 1
## length
## [m]
## 1 1362.259
... 그리고 음모를 꾸몄습니다.
ggplot() +
geom_sf(data = graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), col = 'darkgrey') +
geom_sf(data = graph %>% activate(nodes) %>% as_tibble() %>% st_as_sf(), col = 'darkgrey', size = 0.5) +
geom_sf(data = path_graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), lwd = 1, col = 'firebrick') +
geom_sf(data = path_graph %>% activate(nodes) %>% filter(nodeID %in% c(from_node, to_node)) %>% as_tibble() %>% st_as_sf(), size = 2)
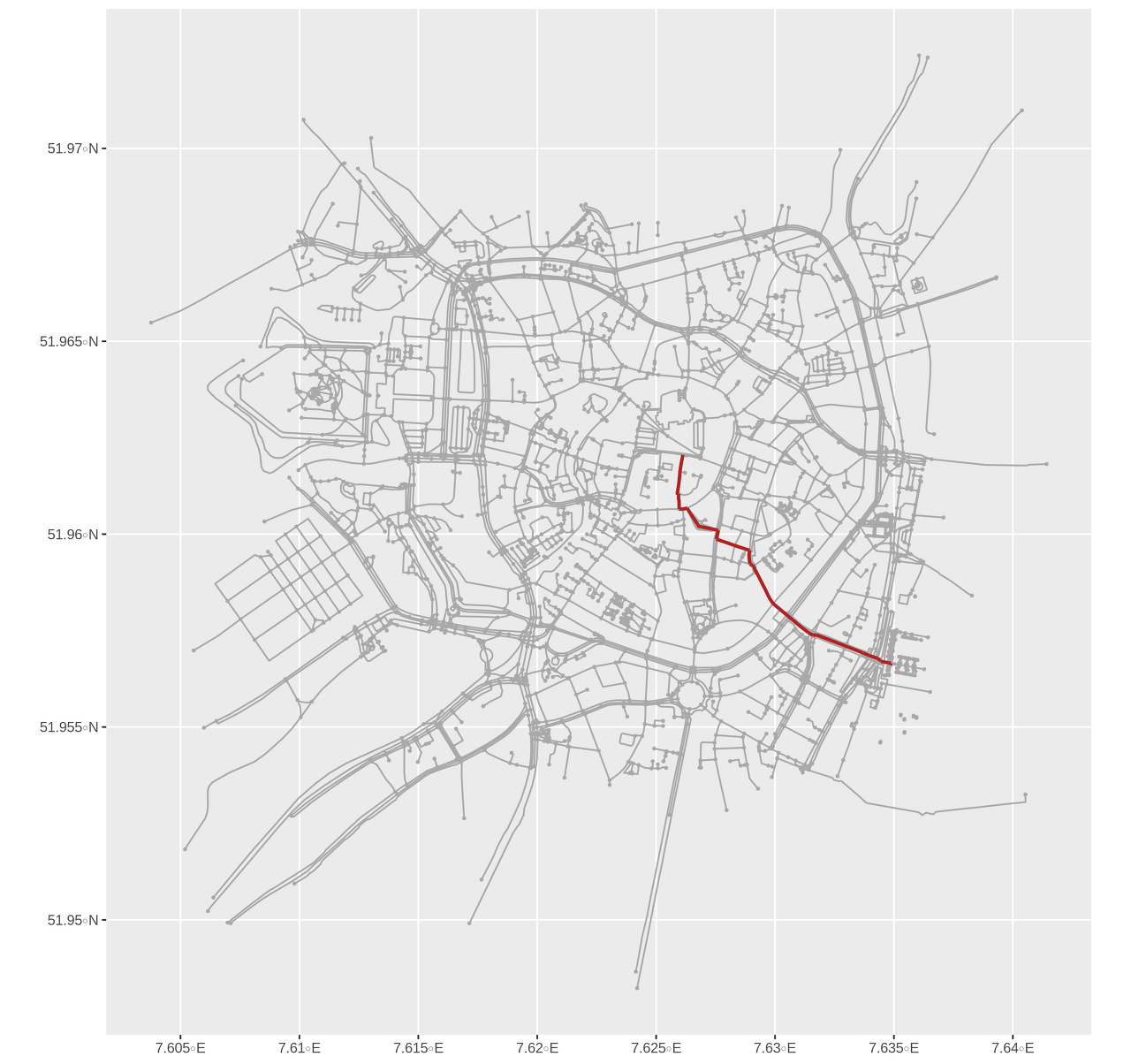
그러나 종종 네트워크의 노드가 아닌 지리적 지점 간의 최단 경로에 관심이 있습니다. 예를 들어, Münster 기차역에서 대성당까지의 최단 경로를 계산할 수 있습니다.
muenster_station <- st_point(c(7.6349, 51.9566)) %>%
st_sfc(crs = 4326)
muenster_cathedral <- st_point(c(7.626, 51.962)) %>%
st_sfc(crs = 4326)
ggplot() +
geom_sf(data = graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), col = 'darkgrey') +
geom_sf(data = graph %>% activate(nodes) %>% as_tibble() %>% st_as_sf(), col = 'darkgrey', size = 0.5) +
geom_sf(data = muenster_station, size = 2, col = 'firebrick') +
geom_sf(data = muenster_cathedral, size = 2, col = 'firebrick') +
geom_sf_label(data = muenster_station, aes(label = 'station'), nudge_x = 0.004) +
geom_sf_label(data = muenster_cathedral, aes(label = 'cathedral'), nudge_x = 0.005)

네트워크에서 경로를 찾으려면 먼저 네트워크에서 가장 가까운 지점을 식별해야 합니다. nabor패키지에는 그렇게 하기 위한 잘 수행되는 기능이 있습니다 . 그러나 출발지와 목적지 노드의 좌표가 행렬에 제공되어야 합니다.
# Coordinates of the origin and destination node, as matrix
coords_o <- muenster_station %>%
st_coordinates() %>%
matrix(ncol = 2)
coords_d <- muenster_cathedral %>%
st_coordinates() %>%
matrix(ncol = 2)
# Coordinates of all nodes in the network
nodes <- graph %>%
activate(nodes) %>%
as_tibble() %>%
st_as_sf()
coords <- nodes %>%
st_coordinates()
# Calculate nearest points on the network.
node_index_o <- knn(data = coords, query = coords_o, k = 1)
node_index_d <- knn(data = coords, query = coords_d, k = 1)
node_o <- nodes[node_index_o$nn.idx, ]
node_d <- nodes[node_index_d$nn.idx, ]
이전과 마찬가지로 ID를 사용하여 최단 경로를 계산하고 플롯합니다.
path <- shortest_paths(
graph = graph,
from = node_o$nodeID, # new origin
to = node_d$nodeID, # new destination
output = 'both',
weights = graph %>% activate(edges) %>% pull(length)
)
path_graph <- graph %>%
subgraph.edges(eids = path$epath %>% unlist()) %>%
as_tbl_graph()
ggplot() +
geom_sf(data = graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), col = 'darkgrey') +
geom_sf(data = graph %>% activate(nodes) %>% as_tibble() %>% st_as_sf(), col = 'darkgrey', size = 0.5) +
geom_sf(data = path_graph %>% activate(edges) %>% as_tibble() %>% st_as_sf(), lwd = 1, col = 'firebrick') +
geom_sf(data = muenster_station, size = 2) +
geom_sf(data = muenster_cathedral, size = 2) +
geom_sf_label(data = muenster_station, aes(label = 'station'), nudge_x = 0.004) +
geom_sf_label(data = muenster_cathedral, aes(label = 'cathedral'), nudge_x = 0.005)
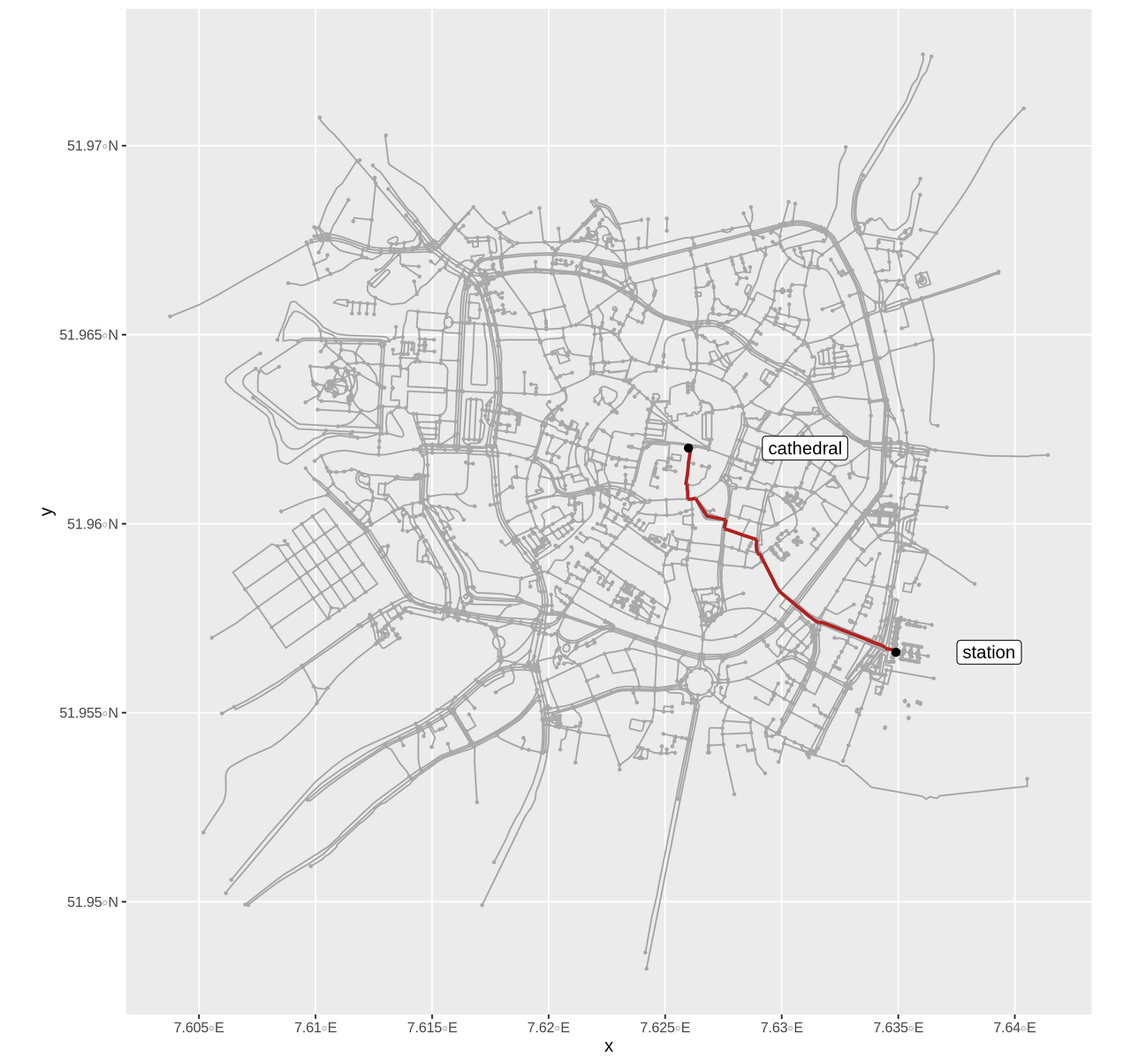
그것은 효과가 있었다! 우리는 기차역에서 중앙까지의 경로를 계산했는데, 이것은 뮌스터를 방문하는 관광객들이 흔히 가는 여행입니다. 분명히 이것은 완성된 작업이 아니지만 게시물은 가능한 것을 보여주었습니다. 미래의 기능은 '가중 프로파일'의 제공, 배치 라우팅 및 R에서 공간 네트워크 데이터로 작업하는 데 필요한 단계 수를 줄이는 기능을 포함하여 공간 네트워크를 보다 사용자 친화적으로 만들어야 합니다.
대안적 접근 및 추가 정보를 위해 다음 리소스를 권장합니다.
- sfnetworks, 이 게시물의 아이디어 중 일부를 구현하는 GitHub 패키지: https://github.com/luukvdmeer/sfnetworks
- stplanr, 공간 / 네트워크 생성 및 작업을 위한 기능 이 포함된 교통 계획 패키지: https://github.com/ropensci/stplanrsfigraph
- dodgr, 방향성 그래프에서 거리 및 기타 출력을 계산하기 위한 패키지: https://github.com/ATFutures/dodgr
- cppRouting, C++에서 라우팅을 위한 패키지: https://github.com/vlarmet/cppRouting
- R을 사용한 지리 계산 10장, 컨텍스트를 제공하고 R의 운송 계획 워크플로를 보여줍니다. https://geocompr.robinlovelace.net/transport.html
출처
'🖥️ IT, 컴퓨터 > 📏 R' 카테고리의 다른 글
| [R] 카카오맵 API를 사용해 지오코딩하기 (주소를 경위도로 변환) (6) | 2022.08.29 |
|---|---|
| [R] R Studio 꾸미기 (TmThemeEditor사용하여 내가 원하는 색으로 바꾸기) (0) | 2022.08.11 |
| [R] R Studio에서 R 파일의 한글이 깨질 때 : 인코딩 reopen, 노트패드 (2) | 2022.08.11 |
| [R] 공간데이터 가공하기 (1) : 속성테이블 정제 (0) | 2022.08.02 |
| [R] 에러 해결 : 열의 개수가 열의 이름들보다 많습니다 in r (2) | 2022.07.07 |

댓글